时间序列分析基础
面向读者:缺少系统 TS 背景、需要先对齐术语与评估体系的研究者与工程师;后续章节默认读者已具备本章的概念基线。
本章回答三个问题:
- 时间序列分析包含哪八类核心任务,它们的形式化定义与主流评价指标是什么?(§1.1)
- 从 ARIMA 到基础大模型,TS 方法论如何沿"统计 → ML → DL → FM"四代演进?(§1.2)
- 预测、分类、异常检测各自使用哪些权威基准,其评估协议存在哪些常见陷阱?(§1.3)
核心任务分类
时间序列分析(Time Series Analysis)涵盖一系列结构各异的机器学习与统计推断任务。本节系统梳理八类核心任务的形式化定义、主流方法及代表性文献,为后续章节的工业场景专题讨论奠定术语基础。这八类任务并非相互排斥,实际工业系统中往往存在任务组合——例如先做插补再做预测,或将预测误差用于异常检测。
1.1.1 预测(Forecasting)
给定历史观测序列 $\mathbf{x}_{1:T} = (x_1, x_2, \ldots, x_T) \in \mathbb{R}^{T \times D}$,其中 $D$ 为变量维度,预测任务的目标是学习映射:
使得预测输出 $\hat{\mathbf{x}}_{T+1:T+H}$ 尽可能接近真实未来值 $\mathbf{x}_{T+1:T+H}$,其中 $H$ 为预测视野(forecast horizon)。
短期预测(Short-term Forecasting)通常 $H \leq 48$(步),关注局部动态,ARIMA、ETS 等统计方法仍具竞争力。长期预测(Long-term Forecasting)$H \in [96, 720]$ 步,模型须捕捉长程依赖,Transformer 系列方法兴起于此背景。
概率预测(Probabilistic Forecasting)输出预测分布 $p(\mathbf{x}_{T+1:T+H} | \mathbf{x}_{1:T})$ 或分位数集合 $\{\hat{q}_\alpha\}_{\alpha \in \mathcal{A}}$,提供不确定性量化(Uncertainty Quantification, UQ)。连续分级概率评分(CRPS)是其综合评价指标:
扩散/流匹配范式近年在概率预测领域快速发展:TimeGrad 以自回归去噪扩散生成未来分布;Sundial(§1.2.6)则采用流匹配(Flow Matching)替代扩散,原生支持概率输出且推理速度更快。LLM 重编程路线(Time-LLM)将时序 Patch 重映射为文本原型(text prototypes)送入冻结 LLM,在零样本/少样本场景下表现突出。
表 1.1.1 主流评价指标
| 指标 | 适用场景 |
|---|---|
| MAE | 鲁棒,不惩罚大误差 |
| MSE | 惩罚大误差,标准基线 |
| MASE | 跨序列可比,M4 标准 |
| WAPE | 供应链、能源预测 |
| CRPS | 概率预测评估 |
代表性方法(节选)
| 方法 | 类型 | 长期 |
|---|---|---|
| ARIMA | 统计 | 弱 |
| N-BEATS | 深度学习 | 中 |
| PatchTST | Transformer | 强 |
| DLinear | 线性 | 强 |
| TimesFM | 基础模型 | 强 |
| Chronos | 基础模型 | 强 |
概率预测在工业场景(如电力调度、供应链)中的价值远超点预测,CRPS 和分位数覆盖率应作为评估的优先指标。长期预测仍是开放问题,线性模型 DLinear 在多个基准上击败 Transformer 的现象值得深思。Mamba/SSM 以线性时间复杂度 $O(T)$ 填补了超长序列场景下 Transformer $O(T^2)$ 的瓶颈,是 2024 年预测方法的重要新支线。
1.1.2 分类(Classification)
给定时间序列样本集合 $\mathcal{D} = \{(\mathbf{x}^{(i)}, y^{(i)})\}_{i=1}^N$,其中 $\mathbf{x}^{(i)} \in \mathbb{R}^{T \times D}$,$y^{(i)} \in \{1, 2, \ldots, C\}$,分类任务学习:
工业场景中的典型应用包括:故障类型识别、设备状态判别、产品质量分级、人体活动识别(HAR)。
特征工程路线依赖手工特征,包括时域特征(均值、标准差、偏度、峰度、过零率)、频域特征(FFT 幅度谱、功率谱密度 PSD)、时频特征(小波系数、STFT)。端到端深度学习路线以 ROCKET 系列和 InceptionTime 为代表,已在大规模基准(UCR 160+ 数据集)上取得 SOTA,且 ROCKET 的训练速度比深度方法快 100 倍以上,其核特征为:
其中 PPV(Proportion of Positive Values)为核激活的正值比例,$w_k$ 为随机初始化的卷积核。
ROCKET 系列以随机卷积核 + 线性分类器的极简架构在 UCR 基准上达到 SOTA,其计算效率使其在工业边缘部署中极具吸引力。端到端深度学习在小样本工业场景中往往不如 ROCKET + 少量标注数据的方案。
1.1.3 聚类(Clustering)
无监督设置下,给定 $N$ 条时间序列 $\{\mathbf{x}^{(i)}\}_{i=1}^N$,聚类任务将其划分为 $K$ 个簇,使簇内相似度最大化、簇间差异最大化。时间序列聚类的核心难点在于相似度度量的选择。
欧氏距离要求等长;动态时间规整(DTW)允许非线性时间对齐:
软 DTW(Soft-DTW)可微分,适合深度学习端到端训练;SBD(Shape-Based Distance)用于 k-Shape 算法,归一化相关性使其对振幅缩放不敏感。代表方法包括:k-Shape(SIGMOD 2015)、TICC(基于图模型的时序片段聚类,KDD 2017)、TS2Vec(对比表征学习,AAAI 2022)。
1.1.4 异常检测(Anomaly Detection)
异常检测是工业时间序列分析的核心任务之一。给定时间序列 $\mathbf{x}_{1:T}$,异常检测任务输出二值标签序列:
其中 $s_t$ 为异常分(anomaly score),$\delta$ 为阈值。按方法原理可分为四大家族,各有不同的核心假设和适用场景。
异常检测没有通用最优方法。工业场景中的关键挑战是:(1) 异常标注极稀缺,需要无监督或半监督方法;(2) 时间依赖性要求模型感知上下文而非逐点判断;(3) 评价协议的选择直接影响方法排名,需谨慎对比。
1.1.5 插补(Imputation)
给定含缺失值的时间序列 $\tilde{\mathbf{x}}_{1:T}$,其中缺失位置集合为 $\Omega^c$,插补任务恢复完整序列:
缺失机制分类来自统计学 MCAR/MAR/MNAR 框架。完全随机缺失(MCAR)是最理想的情形;非随机缺失(MNAR)中缺失依赖于缺失值本身,最难处理,且工业中的传感器故障往往属于此类。
工业常见结构化缺失场景:传感器批量失效(整列缺失)、通信丢包(随机短段缺失)、设备停机(长段有规律缺失)。扩散模型的条件生成框架天然适配缺失数据恢复,CSDI(NeurIPS 2021)和 TIMBA(Mamba+扩散,2024)是代表性工作。
1.1.6 变点检测(Change Point Detection)
变点检测(CPD)识别时间序列中统计特性发生突变的位置集合 $\mathcal{T}^* = \{t_1^*, t_2^*, \ldots, t_K^*\}$:
其中 $\mathcal{C}(\cdot)$ 为代价函数(如负对数似然),$\beta$ 为惩罚项(BIC/AIC 准则)。离线 CPD整段序列一次性处理,追求全局最优,PELT 算法(精确动态规划,$O(T)$)是主流选择;在线 CPD实时处理,CUSUM 和 BOCPD 是代表性方法。与异常检测的区别在于:变点检测关注统计特性的持续性变化,而非单点或短段的异常偏差。
1.1.7 分割与回归(Segmentation & Regression)
时间序列分割(Segmentation)将序列划分为若干语义一致的片段,每段具有同质的统计特性或物理含义。与变点检测的区别在于:分割更关注片段的语义标签,而不仅是边界位置。$\mathbf{x}_{1:T} = \mathbf{x}_{1:t_1} \oplus \mathbf{x}_{t_1+1:t_2} \oplus \cdots \oplus \mathbf{x}_{t_{K-1}+1:T}$。典型应用:工业过程阶段识别、运动阶段分割、医疗状态转换分析。
时间序列回归(Extrinsic Regression)区别于传统预测(预测序列未来值),它预测与序列相关联的外部连续变量,例如由振动信号预测轴承剩余使用寿命(RUL)。这在预测性维护场景中极为重要:$f_\theta: \mathbb{R}^{T \times D} \rightarrow \mathbb{R}$。
1.1.8 因果推断(Causal Inference)
时间序列因果推断旨在识别变量间的因果方向,超越单纯的相关关系。格兰杰因果(Granger Causality)是最经典的操作化定义:
即知道 $X$ 的历史有助于预测 $Y$ 的未来。结构因果模型(SCM)框架进一步建模变量间的因果机制:$x_t^{(i)} = f_i(\mathbf{pa}^{(i)}_t, \epsilon_t^{(i)})$,其中 $\mathbf{pa}^{(i)}_t$ 为变量 $i$ 的因果父节点集合。
工业应用:根因分析(Root Cause Analysis, RCA)是因果推断在工业时间序列中最重要的应用,用于识别生产异常的真实诱因而非表面相关变量。代表方法包括:PCMCI(约束方法,Science Advances 2019)、NeuralGC(神经网络,JMLR 2022)、CUTS(ICLR 2023)。
因果推断在工业场景中具有极高价值,但也面临极大挑战:高维变量、非线性动力学、观测噪声、有限样本。当前深度学习因果发现方法(NeuralGC, CUTS)在合成数据上表现良好,但工业真实数据上的验证仍是开放问题。
1.1.9 基础模型的任务通用性小结
各主流时序基础模型在下游任务上的覆盖并不对称。下表从任务覆盖角度做一次统一盘点,避免读者在每个任务节中分散查找。两条技术路线并行发展:原生 TSFM(TimesFM/Chronos/Moirai)从零在大规模时序语料上预训练,与语言模型无耦合;LLM 适配路线(Time-LLM、GPT4TS)复用冻结 LLM 的序列建模能力,核心假设是"自然语言的长程模式识别能力可迁移至时序"。
| 基础模型 | 预测 | 分类 | 异常检测 | 插补 | 核心说明 |
|---|---|---|---|---|---|
| TimesFM | ● | ○ | △ | ○ | 零样本预测为核心,AD 靠预测误差派生 |
| Chronos | ● | ○ | △ | ○ | 量化 token 语言模型,原生概率预测 |
| Moirai | ● | ○ | △ | ● | 多变量零样本;掩码训练支持插补 |
| MOMENT | ● | ● | ● | ● | 任务覆盖最全的开源基础模型 |
| Timer-XL | ● | ○ | ● | ● | 生成范式统一预测、异常检测与插补 |
| Sundial | ● | ○ | △ | ○ | Flow Matching 概率预测,非扩散模型 |
| Time-LLM | ● | ○ | ○ | ○ | LLM 重编程路线,专注预测 |
● 原生支持并在原论文评估 △ 可派生但非论文主要贡献 ○ 未在原论文覆盖
方法演进脉络
时间序列分析方法经历了从统计模型到机器学习、再到深度学习、最终走向基础模型的四个发展阶段。这四代范式并非替代而是叠加——ARIMA/ETS 与 GBDT 仍在工业中广泛部署,深度学习和基础模型在特定场景下才展现出不可替代的优势。理解这条演进脉络,是判断在特定工业场景选用何种方法的基础。
1.2.1 发展阶段总览
| 维度 | 统计模型 | 机器学习 | 深度学习 | 基础模型 |
|---|---|---|---|---|
| 核心范式 | 假设驱动 | 特征工程 | 表征学习 | 预训练迁移 |
| 数据需求 | 少量 | 中等 | 大量 | 海量(预训练) |
| 可解释性 | 强 | 中 | 弱 | 弱 |
| 跨域泛化 | 弱 | 弱 | 中 | 强 |
| 不确定性 | 原生支持 | 部分支持 | 需要设计 | 部分支持 |
| 工业适用性 | 成熟 | 成熟 | 发展中 | 早期探索 |
1.2.2 第一阶段:统计模型(1970s–2000s)
ARIMA(Autoregressive Integrated Moving Average)由 Box & Jenkins(1976)系统化,是统计预测的奠基性工作。模型定义为 ARIMA$(p, d, q)$:
其中 $B$ 为后移算子,$\Phi(B) = 1 - \phi_1 B - \cdots - \phi_p B^p$ 为自回归多项式,$\Theta(B) = 1 + \theta_1 B + \cdots + \theta_q B^q$ 为移动平均多项式,$\epsilon_t \sim \mathcal{N}(0, \sigma^2)$。季节性扩展 SARIMA$(p,d,q)(P,D,Q)_s$ 在能源、零售等场景中广泛应用。ARIMA 的优势在于统计推断框架完备(AIC/BIC 模型选择、残差诊断、置信区间),但建模流程繁琐,需要平稳性检验(ADF/KPSS)和人工阶数识别(ACF/PACF 图判读)。
ETS(Error, Trend, Seasonality)将经典指数平滑族统一在状态空间框架下(Hyndman et al., 2008),包含 30 种组合(加法/乘法误差 × 无/加/乘趋势 × 无/加/乘季节性),AIC 自动选择最优组合。M4 竞赛(2018)中,经典 ETS 与 Theta 方法仍优于绝大多数深度学习参与方,引发广泛关注。
状态空间模型(State Space Models)在卡尔曼滤波框架下建模:
状态空间模型在处理缺失数据、多变量协同建模和不确定性传播方面具有理论完备性,是 Google Prophet 的数学底层。
统计模型时代奠定了时间序列分析的数学基础:平稳性、自相关结构、不确定性量化。这些概念至今仍是理解深度学习方法局限性的重要参照。M4 竞赛结果表明,在数据量有限、序列独立的场景下,统计方法的竞争力不容忽视。
1.2.3 第二阶段:机器学习方法(2000s–2015)
梯度提升树(GBDT/XGBoost/LightGBM)以加法模型迭代拟合残差:
XGBoost(Chen & Guestrin, KDD 2016)在 M5 竞赛(2020)中仍是强基线,与 LightGBM 一同构成工业界最广泛部署的预测方案。M5 竞赛关键发现:前 50 名几乎全部使用 LightGBM 或其集成,递归特征工程(滞后特征、滚动统计量)是关键,深度学习方案在精度上无明显优势。
ROCKET(Random Convolutional Kernel Transform,Dempster et al., 2020)是机器学习时代的标志性工作,以极简架构在 UCR 85 个数据集上达到当时最优,训练时间比深度方法快 100 倍以上。MiniROCKET(2021)进一步将核集合限定为固定权重,推理速度提升 75 倍,是工业边缘部署的优先选择。
在结构化表格特征工程充分的条件下,梯度提升树在销售预测、能源预测等场景中仍优于深度学习。ROCKET 的成功揭示了一个重要原理:随机特征 + 线性模型在时间序列分类中具有惊人的有效性,这对深度学习的复杂性提供了反证。
1.2.4 第三阶段:深度学习(2015–2022)
LSTM 通过门控机制解决梯度消失,DeepAR 将 LSTM 与概率输出结合,成为亚马逊内部预测系统的核心,首次实现大规模跨品类联合训练。TCN(时间卷积网络)以因果膨胀卷积替代 RNN,实现并行训练,感受野呈指数增长:$\text{RF} = 1 + 2(k-1)\sum_{l=1}^L 2^{l-1}$。
N-BEATS(ICLR 2020)是纯深度学习方法首次在 M4 竞赛上超越统计集成的标志性工作,双重残差连接使前向传播同时产生回溯拟合和未来预测。此后 Transformer 变体潮兴起:Informer 以 ProbSparse Attention 将复杂度从 $O(T^2)$ 降至 $O(T \log T)$;PatchTST 以 Patch 为 Token 并采用通道独立策略;iTransformer 反转注意力方向,以变量为 Token,在多变量预测中表现优异。
Mamba/SSM 的崛起:选择性状态空间模型以线性复杂度 $O(T)$ 处理长序列,离散化后:$h_t = \bar{\mathbf{A}}h_{t-1} + \bar{\mathbf{B}}x_t$,$y_t = \mathbf{C}h_t$。Mamba 的选择性机制($\mathbf{B}, \mathbf{C}, \Delta$ 依输入动态调整)使其在长程依赖任务中填补了 Transformer 的瓶颈。

1.2.5 "Transformer 是否有效"的学术争议
Zeng et al.(AAAI 2023,"Are Transformers Effective for Time Series Forecasting?")以极简线性分解模型 DLinear 挑战 Transformer 主导地位:
DLinear 在 ETT、Exchange、Weather 等多个基准上超越了 Autoformer、FEDformer、Pyraformer 等复杂 Transformer 变体,引发关于"Transformer 是否在时间序列预测中过度设计"的广泛讨论。

| 立场 | 代表工作 | 核心论点 |
|---|---|---|
| 质疑 Transformer | DLinear (AAAI 2023) | 线性模型足够,复杂度无必要 |
| 支持 Transformer | PatchTST (ICLR 2023) | Patch + 通道独立才是关键 |
| 支持 Transformer | iTransformer (ICLR 2024) | 反转注意力方向解决多变量问题 |
| 中立综述 | FITS, TimeMixer | 频域/混合方法各有优势 |
| 实证研究 | Revisiting (TMLR 2023) | 合理配置下 Transformer 仍有效 |
1.2.6 第四阶段:基础模型(2023–至今)
基础模型将大规模预训练的思想引入时间序列领域,旨在构建能够零样本或少样本泛化到新域的通用模型。核心挑战在于:与自然语言不同,时间序列缺乏统一的"词汇表",不同域的序列具有截然不同的量纲、频率和语义。
Chronos(Amazon,TMLR 2024)的核心创新是将连续时间序列量化为离散 token,使用语言模型架构实现原生概率预测:$z = \text{Quantize}(x;\mathcal{B}) = \arg\min_{b \in \mathcal{B}} |x - b|$。MOMENT(CMU,ICML 2024)以掩码重建预训练 + 多任务头,统一了预测、分类、异常检测和插补,是目前任务覆盖最全的开源基础模型。Sundial(清华 THUML,ICML 2025 Oral)采用 TimeFlow Loss(Flow Matching,非扩散),在约 $10^{12}$ 时间步的 TimeBench 上预训练,原生支持概率输出。
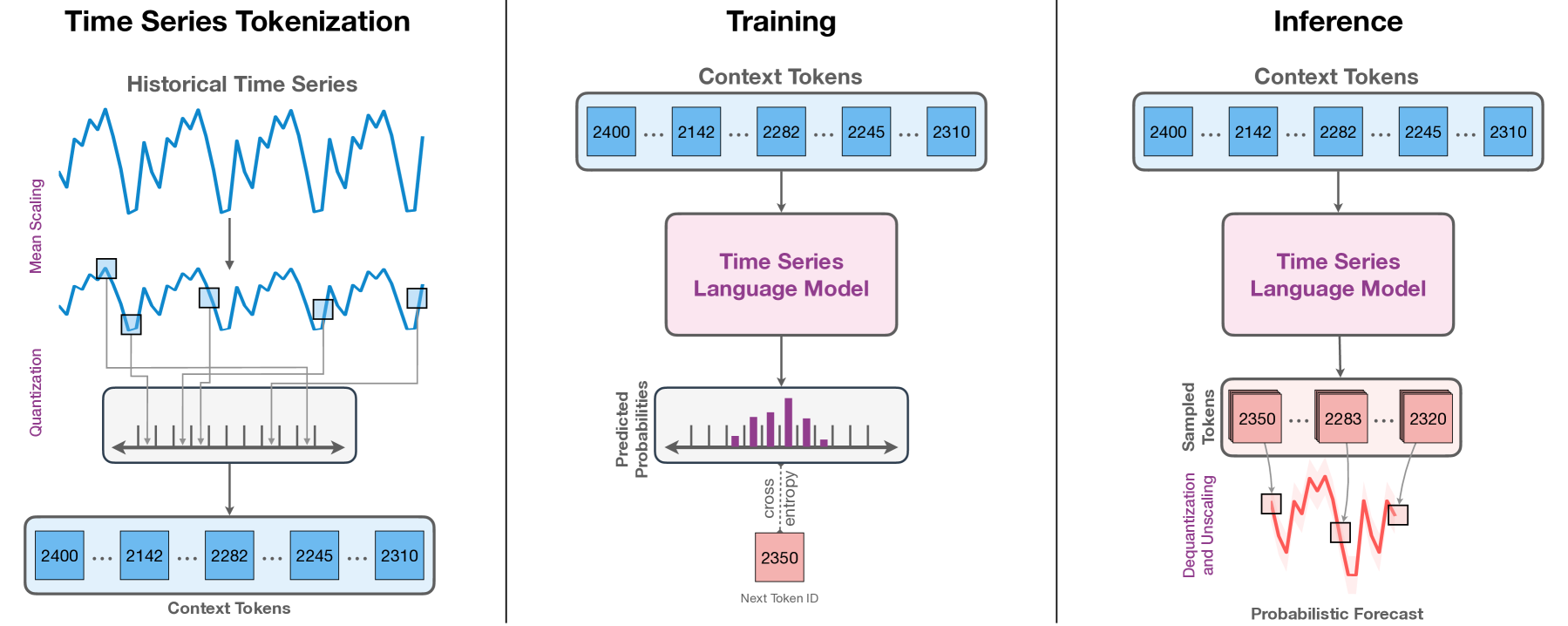
LLM 重编程路线与原生 TSFM 并行发展:Time-LLM(ICLR 2024)将时序 Patch 重编程为"文本原型"送入冻结 LLaMA/GPT-2,辅以 Prompt-as-Prefix 技术引导 LLM 推理,在零/少样本预测中超越多个专用模型。然而 Gruver et al.(NeurIPS 2023)发现大型语言模型在零样本时序预测中仅具备有限能力,尤其在高频工业信号上迁移效果不佳。
| 模型 | 机构 | 参数量 | 概率输出 | 多变量 | 预训练数据规模 |
|---|---|---|---|---|---|
| TimesFM | 200M | 否 | 否 | ~1000亿步 | |
| Chronos | Amazon | 20M–710M | 是 | 否 | LOTSA 等 |
| Moirai | Salesforce | 14M–311M | 是 | 是 | LOTSA 270亿步 |
| MOMENT | CMU | 385M | 否 | 是 | Time-Series Pile |
| Timer-XL | 清华 | 84M | 否 | 是 | UTSD 10亿+步 |
| Sundial | 清华 | 128M | 是 | 是 | TimeBench 万亿步 |
时序基础模型仍处于快速发展阶段,零样本能力接近但尚未全面超越传统统计方法(GIFT-Eval 结论)。工业应用关键问题:领域适应、细粒度可控性、推理延迟。工业数据的系统性缺失(高频、高维、保密)是当前最大的能力天花板。
基准与评估体系
基准数据集(Benchmark Datasets)与评估协议(Evaluation Protocols)是时间序列研究可复现性与方法可比性的基础。本节系统梳理各主要任务领域的权威基准,分析其规模、来源与适用场景,并指出常见评估陷阱。
1.3.1 预测基准
M 竞赛系列(M1–M5)由 Spyros Makridakis 教授主导,自 1982 年起每隔数年举办,是预测领域历史最悠久、影响最深远的评估体系。M4 的 OWA(Overall Weighted Average)综合指标以朴素季节性方法(Naïve2)为归一化基准:
M5(2020)包含 Walmart 零售销售的 42,840 条层次时间序列,并提供价格、促销、日历(节假日)等外生特征,是最接近工业零售预测实际的基准。前 50 名几乎全部使用 LightGBM 或其集成,递归特征工程(滞后特征、滚动统计量)是关键。
ETT 数据集(Electricity Transformer Temperature,Informer 附带)是长期预测研究的事实标准,包含 4 个子集(ETTh1/h2/m1/m2),变压器温度数据,7 变量。标准测试配置(输入长度 336/512,预测步长 96/192/336/720)已被数十篇论文采用。注意:ETT 数据集规模较小,结果方差较大,不宜作为唯一基准。
Monash 时间序列存档(Godahewa et al., NeurIPS 2021)汇聚 30+ 个数据集,涵盖能源、交通、经济、气象等领域,提供统一的数据格式(.tsf)和评估脚本,是验证基础模型零样本泛化能力的标准测试床。GIFT-Eval(Aksu et al., 2024)是专为时序基础模型设计的综合评估框架,覆盖 23 个数据集、多频率、点预测与概率预测,三种设置(零样本、5-shot、全数据微调)。
1.3.2 分类与聚类基准
UCR 时间序列档案(Dau et al., 2019)是时间序列分类研究的黄金标准,由 UC Riverside 的 Eamonn Keogh 教授团队维护,2023 版已达 160+ 数据集,覆盖传感器/设备、医疗/生物、运动/姿态、图像轮廓、电力/能源等领域。UEA 多变量档案(Bagnall et al., 2018)将 UCR 扩展至多变量场景,30 个多变量时间序列分类数据集。
MONSTER(Middlehurst et al., 2024)是对 UCR/UEA 的重要升级,整合超过 200 个数据集(包含大型工业级数据集),标准化交叉验证协议,同时报告计算时间(计算公平性),覆盖分类、聚类、外部回归三种任务。
1.3.3 异常检测基准
SMAP 与 MSL(NASA,KDD 2018 整理)是多元遥测传感器数据,包含点异常与段异常,标注来源于真实故障记录。SMAP 55 个实体、562,800 时间步,异常率 12.8%;MSL 27 个实体、132,046 时间步,异常率 10.7%。PA 协议在此数据集上被广泛使用但争议显著。
TSB-AD(Liu & Paparrizos, NeurIPS 2024,"The Elephant in the Room")是迄今规模最大、质量最受关注的时序异常检测基准之一:来自 40 个数据集的 1,070 条高质量时间序列,推荐 VUS-PR 替代 F1-PA。关键发现:简单统计方法和轻量架构在多数子集上仍优于复杂神经网络。
TimeSeriesBench(Si et al., 2024)面向工业运维,来自真实在线系统的多变量监控指标,提供 All-in-One(统一模型)和 Zero-Shot 两种评估范式,168+ 评估设置,是目前最贴近工业需求的 AD 基准。
1.3.4 评估陷阱与最佳实践
TSAD-Eval(Schmidl et al., VLDB 2022)对 158 个时间序列异常检测算法在 967 个数据集上进行了迄今最大规模的系统评估,核心发现:没有任何单一方法在所有数据集上最优;简单的统计基线(Moving Average、IQR)在部分子集上优于深度方法;评估协议(PA vs non-PA)对排名影响极大。
评估体系的质量直接影响研究结论的可靠性。工业时间序列研究者应优先选择 TimeSeriesBench、GIFT-Eval 等新一代基准,这些基准在数据质量控制和评估协议设计上更贴近工业需求。对于任何在特定基准上声称"SOTA"的方法,应检查评估协议细节,尤其是 PA 协议的使用。
本章小结
📌 核心 Takeaway
时间序列分析不是单一任务,而是由预测、分类、聚类、异常检测、插补、变点、分割与因果推断八个形式化任务构成的方法谱,每个任务都有自己独立的损失函数、评估指标与基准生态——任何跨章节的方法讨论都应先回到这八类任务的区分。
从方法论图景看,本章勾勒了一条清晰的演进主线:ARIMA/ETS → GBDT/ROCKET → LSTM/Transformer/Mamba → TimesFM/Moirai/Chronos/Sundial,各自以不同方式权衡"结构先验 vs 数据规模"。DLinear、N-BEATS、GBDT 在相当多的基准上仍能与更复杂的模型并驾齐驱——方法新颖性并不天然等于精度优势。
本章留下的开放问题:现有基准多以学术开放数据为主,工业毫秒–秒级高频、数百–数千通道、事件驱动的时序几乎缺席;PA 等评估协议的滥用仍在虚增异常检测论文的 F1;基础模型的"零样本 SOTA"在严格去污染后往往显著退化。